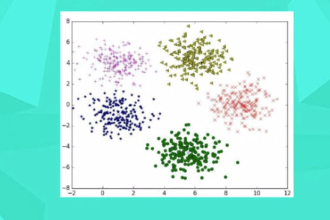
一分鐘了解K均值聚類算法
103
0
展開
下載
收藏
分享
版權說明